ORDAのクエリとそのオプションの紹介です。(原文)
概要
ORDAの中のクエリはdataclass.query()メソッドを実行します。このquery()メソッドは検索条件としてクエリ・ストリングを使います。クエリ・ストリングには主に3つの必須のパラメータが含まれています:アトリビュート・パス、比較演算子、値と結合クエリの論理演算子。これら4つのパラメータを使うことで、開発者は、深いパスとドット記法で使われる複雑なロジックでクエリを構築することができます。クエリ・ストリングのシンタックスは、4D開発者の多くにとって全く新しいもので、4Dランゲージのクエリとは異なります。このテックノートは、クエリ・ストリング構築の最適な手段と、有効でありながらあまり知られていないクエリ・オプションを掘り下げることを目的としています。Query()の現行のドキュメントより詳しく既存のオプションの使い方を提示し、ドキュメント化されていない役に立つオプションを紹介します。
はじめに
dataClass.query()とは何か?
ORDAでは、dataclass.query()メソッドは、特定のdataClassの全てのエンティティの中で、クエリ・ストリングに記述された検索条件をベースにしたエンティティの検索に使われます。Query()の結果は該当するエンティティを含むentitySelectionになります。EntityCollectionは、もし該当するエンティティが見つからなければ空になります。例えば、以下のコードはEmployeeというデータクラス上でquery()メソッドを呼んで、Genderフィールドに”Male”という値を持つ全てのエンティティに対してクエリします:
$employees_ORDA_o:=ds.Employee.query(“gender = Male”)
dataclass.query()メソッドは一つの必要なパラメータqueryStringを持ち、二つのオプショナルなパラメータvalueとquerySettingsを持っています。QueryStringパラメータは、検索条件を記述するのに使用します。Valueパラメータはプレースホルダーと共にクエリ・ストリングに値を渡すのに使用されます。querySettingsは、例えばqueryPathやqueryPlanを有効にするといった、クエリ設定を追加するために使用します。
QueryStringパラメータは、クエリ・ストリングによって表現される複雑な検索条件に適用できるように、様々なオプションを提供します。以下は、全ての非管理職の雇用者で30歳以上、4Dという会社で、John Smithマネージャーと仕事をしている者をクエリするサンプルです:
$employeesSel:=ds.Employee.query(“company.state = ‘California’ AND gender = ‘Male’ AND title = ‘@Engineer@’ AND manager.lastName = ‘s@’ ”)
最適なクエリを実行し、正確な結果を得る鍵は、効果的なクエリ・ストリングを構築することです。
クエリ・ストリングとは何か?
Query()のqueryStringパラメータは、4つのオプションから成る以下のシンタックスを持っています:
attributePath comparator value {logicalOpertor attributePath comparator value}
- attributePath: クエリを実行するためのデータクラス属性のパス。最初のレベルの属性は、”gender”のような、属性の名前です。関連するクラスの属性に対しては、”company.name”のようにドット記法を使って表現されるパスになります。
- comparator: 比較演算子の記号はattributePathと値を比較するのに使われます。対応している記号は、=、==、===、#、!=、<、>、<=、>=、%、あるいはキーワードのIS、IS NOT、IN、NOTです。
- value: 値は、attributePathに従ってクエリされたエンティティの値と比較されます。ターゲット値のタイプに合致するストリング表現でなければなりません。例えば、データ値が”YYYY-MM-DD”形式である必要があり、時間は秒に置き換える必要があります。ワイルドカード文字”@”が使えます。
- logicalOperator: 論理演算子は、必要であればクエリの中で複数の条件を組み合わせるのに使われます。二つの演算子が使用できます、AND (&, &&, and)とOR (|, ||, or)です。
QUERY/QUERYBY ATTRIBUTEコマンドとの違い
dataclass.query()メソッドは、entitySelectionを検索するためにORDA用にデザインされています。比較や論理演算子(接続詞)の記号など4DランゲージのQUERYコマンドに似ています。しかし、シンタックスや機能はQUERRYコマンドとは全く異なります。QUERYとquery( )の間の主な相違点をサンプルで見てみましょう。以下は二つのテーブル:PeopleとHealthRecordを持つストラクチャーです。HealtRecordテーブルは、プロパティにprescriptionとsymptomsがある二つのコレクションを持つadditionalInfoオブジェクト属性を持っています:
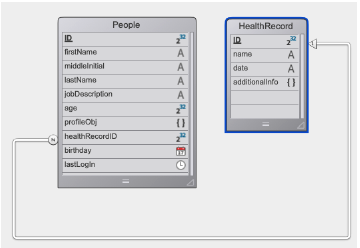
下記はentitySelectionを検索するクエリで、患者の中で名前がRyanもしくはKevinで、現在クラリンチンという薬を摂取していて、症候的な熱がある人を検索します。
$result:=ds.People.query(“firstName in :1 AND
healthrecord.additionalInfo.prescription [ ].drugName in :2 AND
healthrecord.additionalInfo.symptoms [ ] =fever”;new object” (“parameters”; new collection (new collection (“Ryan” ; “Kevin”); new collection (“Clarintin”, “Tyleol)))
QUERYとQUERY BY ATTRIBUTEコマンドで同じ検索条件を使って、セレクションを入手するために、以下のコードを書きます:
QUERY ( [People];[People]firstName=”Ryan”;*)
QUERY ( [People]; | ; [People]firstName=”Kevin”;*)
QUERY BY ATTRIBUTE ([People];[HealthRecord] additional Info;”prescription [ ].drugName”; = ; “Clarintin”)
QUERY BY ATTRIBUTE ([People];[HealthRecord]additionalInfo;”symptoms[ ]”;=;”fever”)
おそらくお気付きのように、query( )とQUERYの間にはいくつか明確な違いがあります:
-
query( )検索条件は一行で構成される: 上記でデモしたように、query( )の検索条件は一行で構成されます。必要なときには、論理演算子(接続詞)を前の値の最後に追加します。 この機能によってプログラム的に複雑なストリングを構築するのがよりフレキシブルになります。
-
マルチレベル・リレーション・クエリはattributePathを使ってより読みやすく:
QUERYコマンドにはリレートテーブルを複数のレベルで検索する機能がある一方、query( )のattributePathの中のドット記法はもっと多くのパスを作ります。例えば、多対個リレーション[City] → [Department] → [Region] を持つ3つのテーブルに対して、以下のQUERY:QUERY ([Region];[City]Name=”Saint@”)と、以下のquery( )メソッド:
ds.Region.query(“department.city.name = ‘Saint@’”)は同じレコードをセレクションとentitySelectionからそれぞれ検索します。query( )メソッドのattributePathはドット記法を使って、対象となる属性(Region.department.city.name)のフルパスを名前のついたリレーションを経由して反映します。attributePathは、論理演算子と共に接続に使われるときに、開発者に高度な可読性を持った複雑なクエリを可能にします。
query( )はキーワードの”IN”、”NOT”とコレクションを使って一つ以上の検索に対応する:
query( )メソッドは、コレクションを使った検索条件に対して、一度に複数の値を渡すことができます。例えば、以下のクエリはPeopleクラスの中でKimあるいはJohnと属性値が等しいものを見つけます:
$entitySelection:=ds.People.query(“firstName in :1”;New collection (“Kim”;”John”))
最適化したクエリ・ストリングを構築して正確な結果を得る
上記でデモしたように、複数のパートを持つquery( )メソッドの検索条件は、一つのクエリ・ストリングに適合できます。開発者は4つの可能なオプションを使って、よりフレキシブルにクエリ・ストリングを構築することができます。
この章では、まだドキュメント化していない、私が自身の経験から集めたいくつかのベストプラクティスを提示します。このベストプラクティスを実装することで、query( )の実行中に正確性とパフォーマンスの両方を向上する最適なクエリを構築できる可能性があります。
複数のクエリ条件を外すために比較演算子NOTを使う
(query( )では新しい)比較演算子NOTは以下のクエリを外すのに使われるということがドキュメントに書かれています。例えば以下のクエリは、firstNameが”Aaron”ではないエンティティを見つけます:
$result:=ds.Employee.query (“NOT (firstName = Aaron)”)
また同じくドキュメント化されていますが、複数のクエリは論理演算子ANDとORを使ってつなぐことができます。これは論理演算子で繋がった複数のクエリにNOTが使えるということです。以下のクエリで、NOTが使われていないとき、クエリはIDが3より小さい、IDが3より大きい、あるいは等しい、lastNameがSmithかBlazerと等しい、そしてfirstNameがAaronに該当する、全てのエンティティを見つけます:
$result:=ds.Employee.query(“ NOT (lastName = Smith OR lastName= Blazer AND firstName = Aaron OR ID > 3)”)
NOTを使ったクエリは、各比較/論理オペレータを置き換えた、以下のクエリと同等です:
$result:=ds.Employee.query(“ lastName # Smith AND lastName # Blazer OR firstName # Aaron AND ID >= 3”)
クエリにNOTが使われているとき、クエリ条件は反転し、IDが3以上、lastNameはSmithでもBlazerでもなく、firstNameはAaronではないエンティティを探します。この実験は明白ですが、多くの開発車が見逃しているかもしれません。正しく使えば、検索範囲を狭めて検索の正確性を高めることになります。
新しいEXCEPT論理演算子を複合クエリで使う
ANDとORの他に、query( )はAND NOTを接続詞として使うこともできます。以下の検索条件を排除するのに使えます。キーワード”EXCEPT”と記号”^”はAND NOTの二つのショートカットです。例えば、以下のクエリはIDが1より大きく、ファーストネームに”a”が含まれない人を全て見つけます:
$result_1:=ds.Employee.query (“ID < 100 AND NOT firstName = @a@”)
$result_2:=ds.Employee.query (“ID < 100 EXCEPT firstName = @a@”)
$result_3:=ds.Employee.query (“ID < 100 ^ firstName = @a@”)
// 上記の3つのクエリは同等で同じ結果を得られます。
INステートメントをコレクションと一緒に使って、クエリの範囲をさらに減らす
ドキュメントにも詳しく書かれていますが、INステートメントは、値のコレクションが検索条件に渡される時に使います。Query( )は、コレクションの中の全ての値に対してattributePathが合致します。例として、以下のサンプルは、会社名が4DもしくはWakandaの全ての雇用者を見つけます。
$entitySelection:=ds.Employee.query ( “company.name in :1” ;New collection (“4D”; “Wakanda”))
IN比較演算子が使われた時、コレクションはクエリ条件の一部として渡すことができません。プレースホルダーの使用が必要となります。
// サポートしていない
$companySel:=ds.Employee.query( “company.state in new
collection (“Montana” ; “Maine” ; Florida”)”);
//サポートしている
$companySel:=ds.Employee.query( “company.state in :1” ; new
collection (“Montana” ; “Maine” ; “Florida”));
IN を使った複数のクエリは、論理演算子を使ってまとめることができます。各クエリの値のコレクションは、後続のプレースホルダーを使って渡すことが必要です:
$result:=ds.People.query (“firstName in :1 AND lastName in :2” ;New collection(“Aaron”; “John”);New collection(“Smith” ;”Blazer”))
クエリの値はたいがい値のリストから出てくるので、この比較演算子はとても有用な機能です。値のコレクションはコードを使ったエンティティから構成されたり、あるいはArrayから変換されたり、他のメソッドから返されたりできます。実際にやってみると、コレクションは一般的に他のクエリなど、他のメソッドから生成されます。以下は最初のクエリの結果を第二クエリの値のコレクションに使った例です:
$companySel:=ds.Company.query(“city = ‘San Jose’”)
$employeeSel:=ds.Employee.query(“company.name in :1”;$companySel.name)
EntitySelectionの有効なプロパティ名がドット記法を通じてアクセスされている場合、プロパティ値のコレクションを作成します。この場合、$companySel.nameは、Employee query ( )の中で使用できる会社名のコレクションを返します。
null値を伴うクエリ属性
ドキュメントにも書かれていますが、nullキー語句はNullと未定義の値を含むクエリ属性として使用することができます。例えば、以下のサンプルは配偶者属性がnullのPersonエンティティを返します。
$singlesSel :=ds.People.query(“spouse = null”)
しかし、ORDAの中の全てのタイプのデータがnullや未定義の値をサポートするわけではありません。これらの値が未定義もしくは削除された間にアクセスされた場合、4Dは代替として初期値を使用します。異なるタイプの中にヌル値を持つ、保存された属性をクエリするには、異なるnull値が必要です。以下は、テキスト、数値、時間、日付やオブジェクトなど、いくつかの一般的なタイプに対するnull値をクエリするためのサンプルです:
//空のストリング’ ‘を使ってAlpha/Text値をクエリする
$noFirstNameSel:=ds.People.query (“firstName = ‘ ‘ “)
//nullの数値をクエリするのに0 を使う
$noAgeSel:=ds.People.query(“age = 0”)
//nullの時間の値をクエリするのに0を使う
$noTimeSel:=ds.People.query(“lastLogIn = 0”)
//nullの日付の値をクエリするのに”00/00/00”を使う
$noDateSel:=ds.People.query(“birthday = 00/00/00”)
//nullのオブジェクトをクエリするのに空のオブジェクト・シンタックス”{ }”を使う
$noObjSel:=ds.People.query(“profileObj = { }”)
クエリ結果をソートする
dataclass.query()は、クエリ・ストリング中のステートメントに‘order by’が使えて、クエリ結果をソートできます。Order byステートメントは二つのオプションの特定が必要です:’desc”は降順で、’asc’は昇順です。初期値では昇順になっています。以下はクエリ結果を降順にする使用例です:
$result:=ds.People.query(“ID >1 order by ID desc”)
Order byステートメントは、クエリ・ストリングの最後に追加しなければなりません。Order byの後で追加されたクエリは全て無視されます:
//このクエリは以前のものと同じ結果になります
//order by:の後の”AND firstName # Aaron”は無視されます
$result:=ds.People.query(“ID > 1 order by ID desc AND firstName # Aaron”)
//このクエリが動作します
$result:=ds.People.query(“ID > 1 AND firstName #Aaron order by ID desc”)
query( )でorder byを使うのは、検索したentitySelection上でOrder By( )をコールするのと同じ効果があります。しかし、クエリにOrder byステートメントを加えることで、4Dデータエンジンはソートされたセレクションの生成しかしません。ソートしないセレクションのコピーなしに両方を別々にコールするより少しだけ良いパフォーマンスになります。しかし、文中のorder byを使うと、コードはよりコンパクトで読みやすくなります:
//以下のクエリは同じ結果を生みます
$orderedResult:=ds.People.query (“ID > 1 order by ID desc”)
$orderColl:=New collection
$result:=ds.People.query(“ID > 1”)
$sortedReslt:=$result.orderBy($orderColl.push(New
object (“propertyPath”;”ID”;”descending”;true)))
// $orderedResultと$sortedResultは同じ結果を持ち、両方ともソードされる
// ソートされていないエンティティ・セレクションは$resultでのみ可能
概論と結論
v17のORDAは、オブジェクト志向アプローチを使うデータアクセスの新しい方法として導入されたというだけではありません。クエリを実行するまったく新しい方法としての門戸も開きました。それはデータ駆動アプリケーションのコアでもあります。新しいdataclass.query()メソッドは、いくつものオプションを提供し、4D開発者には親しみやすく、QUERYコマンドのように4Dデータベースのクエリに順応できます。同時に、開発者にとって複雑なクエリの構築をわずかなコードで可能にし、さらにフレキシブルにしました。QUERYのシンタックスを理解し、そのオプションを全て利用することで、ORDAは、より少ないメモリスペースを使って、複雑なクエリをより速く実行することができます。さらに重要なのが、一行に収まる直接的なクエリ・ストリングで高度な可読性を提供することです。
このテックノートは、私の経験に基づいてクエリ・ストリングを構築するベストプラクティスを紹介することが目的です。いくつかのオプションはドキュメント化されていますが、詳細は説明されていませんし、他のオプションにもまだドキュメントになっていないものがあります。ORDAとQUERYメソッドは将来のバージョンでより機能を増やして進化し続けるでしょう。QUERYメソッドは複雑なクエリをシンプルな言語で書く無限のキャパシティがあります。