データベース破損時に便利な 4Dの機能のうち、ミラーリングについての詳しい紹介です。(原文)
はじめに
4Dデータベースは、シンプルにデータを保存したり、データを操作したり、ユーザーにサービスを提供したりするためのツールとして、システムや事業運営に欠くことのできないものです。基幹システムなど、データベースの役割が重要であればあるほど、常時稼働が要求されます。しかし、マーフィーの法則のとおり、「失敗する可能性のあるものは、失敗する」ものです。不測の事態に備えて、緊急時の行動手順を確認しておくことはとても重要です。
このテクニカルノートは、二部構成のシリーズの第二部です。第一部では、データベースが破損した場合に実行できる修復方法をいくつか提案しました。それら修復プロセスの多くは、データベースのサイズに応じて相応のダウンタイムを発生させます。もっとも少ないダウンタイムでデータベースを復旧できる方法として検討すべきなのがミラーリングです。ミラーリングは、データベースの高可用性と安定性を実現するだけでなく、冗長化によってデータ保護を強化し、さらにはバックアップへの依存を減らすことで、バックアップ実行によるデータベースのロックやディスク使用量の増加を防ぐ効果もあります。
ミラーの実装
ミラーの設定と利用には計画が必要です。このセクションでは典型的なミラーの構成について説明します。
アプリケーションの複製
ミラーリングは、同じデータベースをオリジナルと複製という2つのインスタンスの形で維持することで行われます。オリジナルはメインデータベースとしてユーザーの操作を受け付けます。複製はミラーデータベースとなり、メインと同一のデータを維持しつつ、緊急事態に備えてスタンバイします。ハードウェア障害への対策として、両者は互いに通信する手段を持った2つの異なる物理マシン上で実行することが強く推奨され、通常は下図のように、二つの4D Serverが別々のマシンで運用されます。
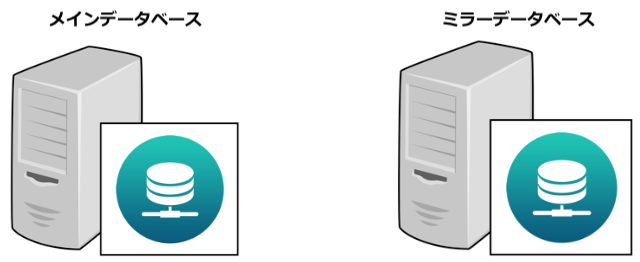
< 図 1 : 二つの4D Serverは別々のマシンで実行 >
データベースには、自己がメインサーバーまたはミラーサーバーのいずれかを識別できるようなコードが必要です。これは様々な方法でできます。簡単な方法は、サーバー起動時にファイルやフォルダーの存在によって判別させることです。
データ同一性の維持
ミラーリングの特徴の一つは、同一のデータセットを維持するデータベースが二つ存在することです。メインデータベース上で行われたデータ操作は、ミラーデータベースにプッシュされて再現され、結果的に同じデータが維持されます。ミラーリングにおけるデータ維持の手法として、ホットスタンバイとウォームスタンバイがあります。ホットスタンバイでは、メインで実行された操作は即座にプッシュされ、データベースの緊密な同期が得られます。ウォームスタンバイの場合、同期はもっと緩やかな間隔で行われるため、最新のデータ操作がミラーデータベースに含まれていない場合があります。
4Dにはウォームスタンバイによるデータギャップをある程度補える機能があるため、通常はウォームスタンバイのミラーを設定します。
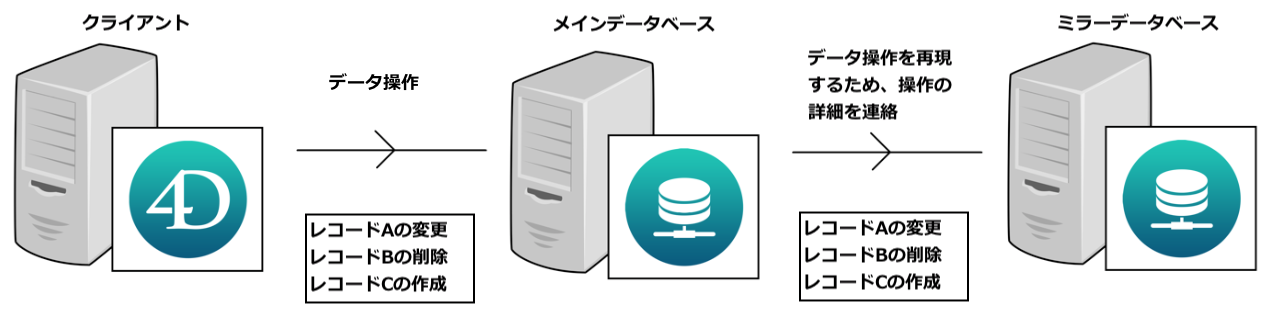
< 図 2 : ミラーリングプロセスの一般的なワークフロー >
具体的には、データは以下のようにプッシュされます:
1. メインデータベースでデータが編集され、カレント・ログファイルに記録されます。
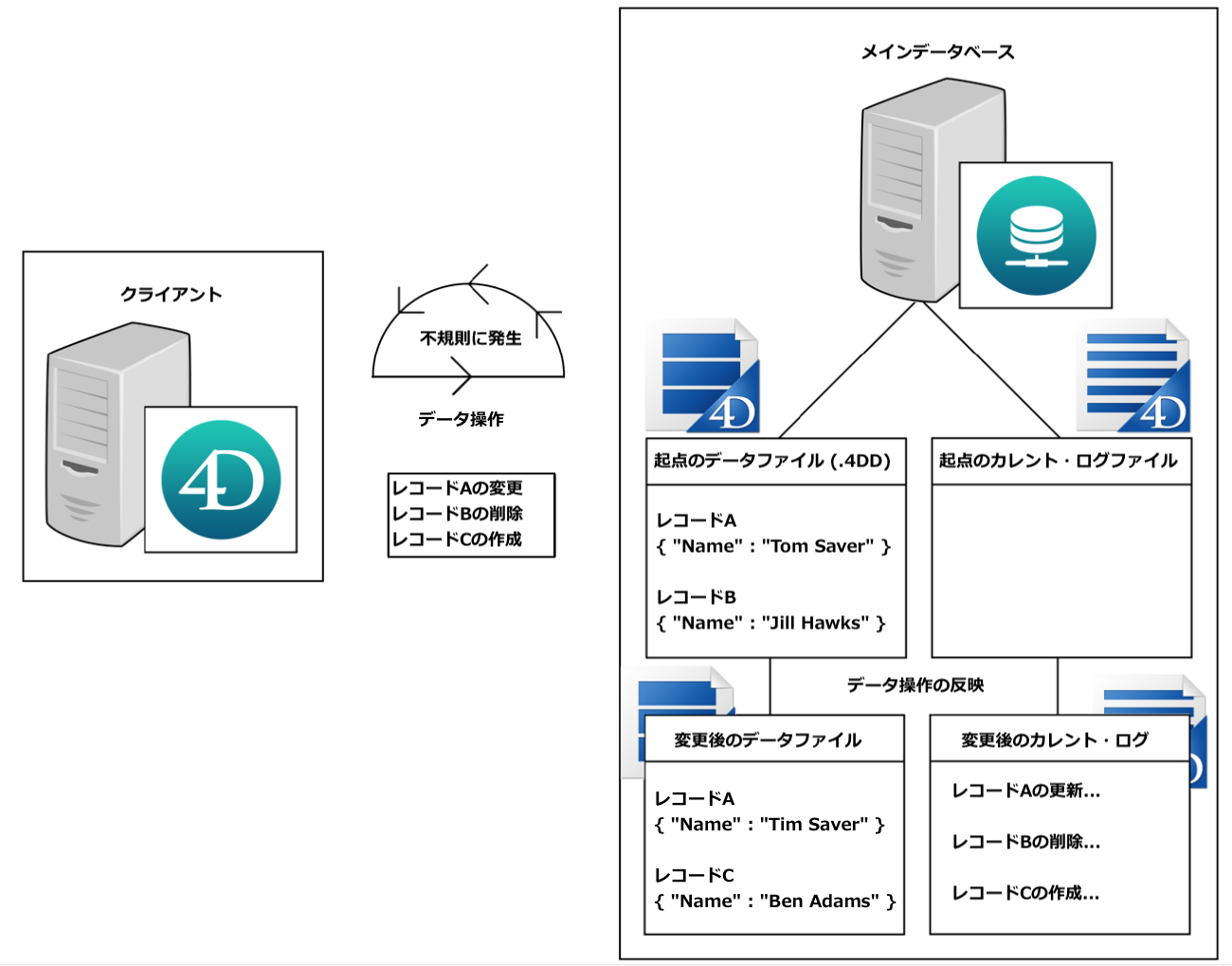
< 図 3 : データ操作によるデータファイルとログファイルへの影響 >
2. 設定した時間が経過すると、New log fileコマンドによってカレント・ログファイルが閉じられ、新しいログファイルが開始されます。これは通常、ストアドプロシージャーによって定期実行されます。閉じられたログファイルは何らかの形でミラーに転送されます。メインサーバーが共有の場所に送信する、あるいはミラーの方から取得しにいくなど、様々な方法で実現できます。
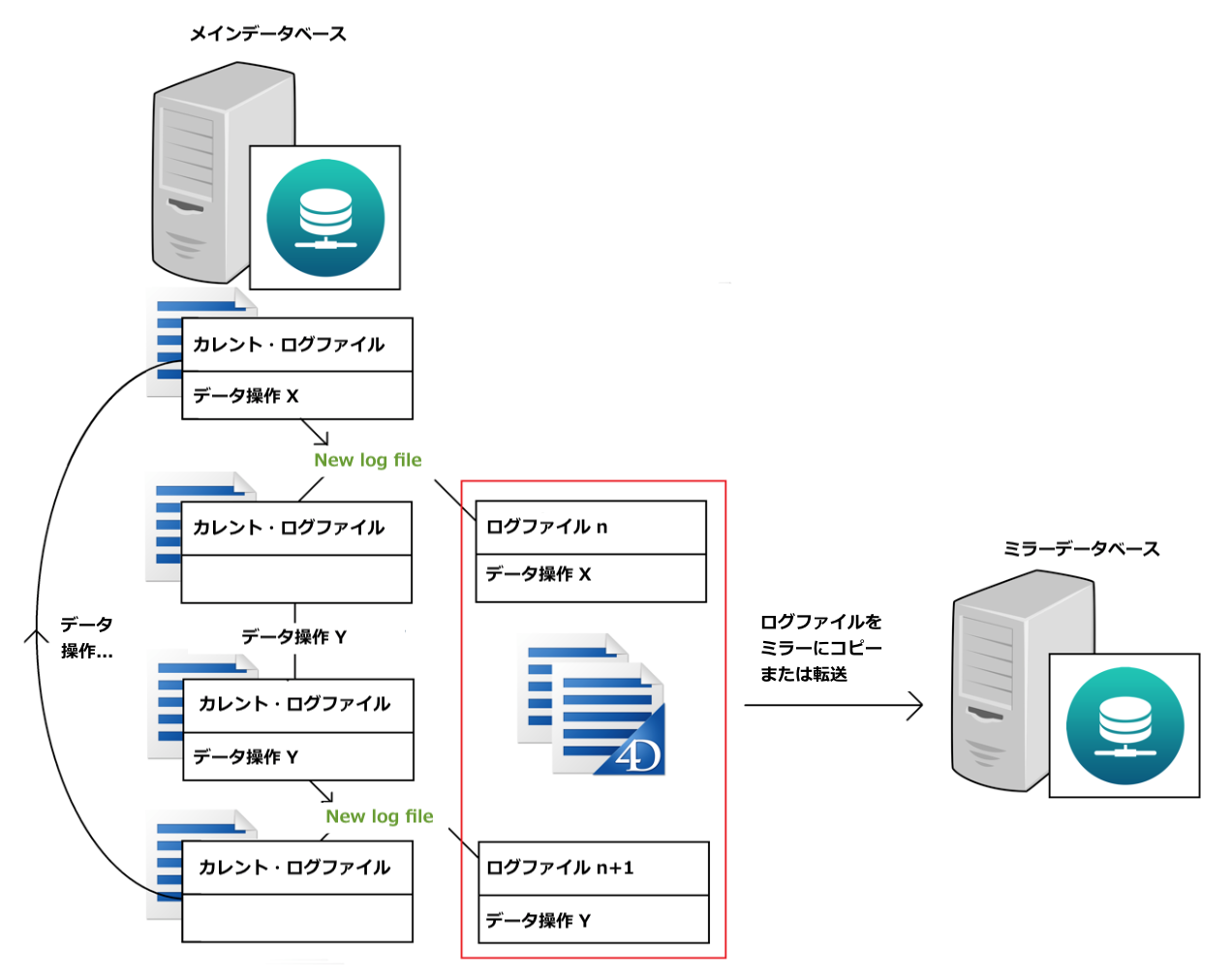
< 図 4 : 定期的なログの生成とミラーへの送信 >
3. ミラーサーバーは、新しいログファイルの存在を定期的にチェックし、INTEGRATE MIRROR LOG FILEコマンドを使って、ログに保存された操作を再現します。
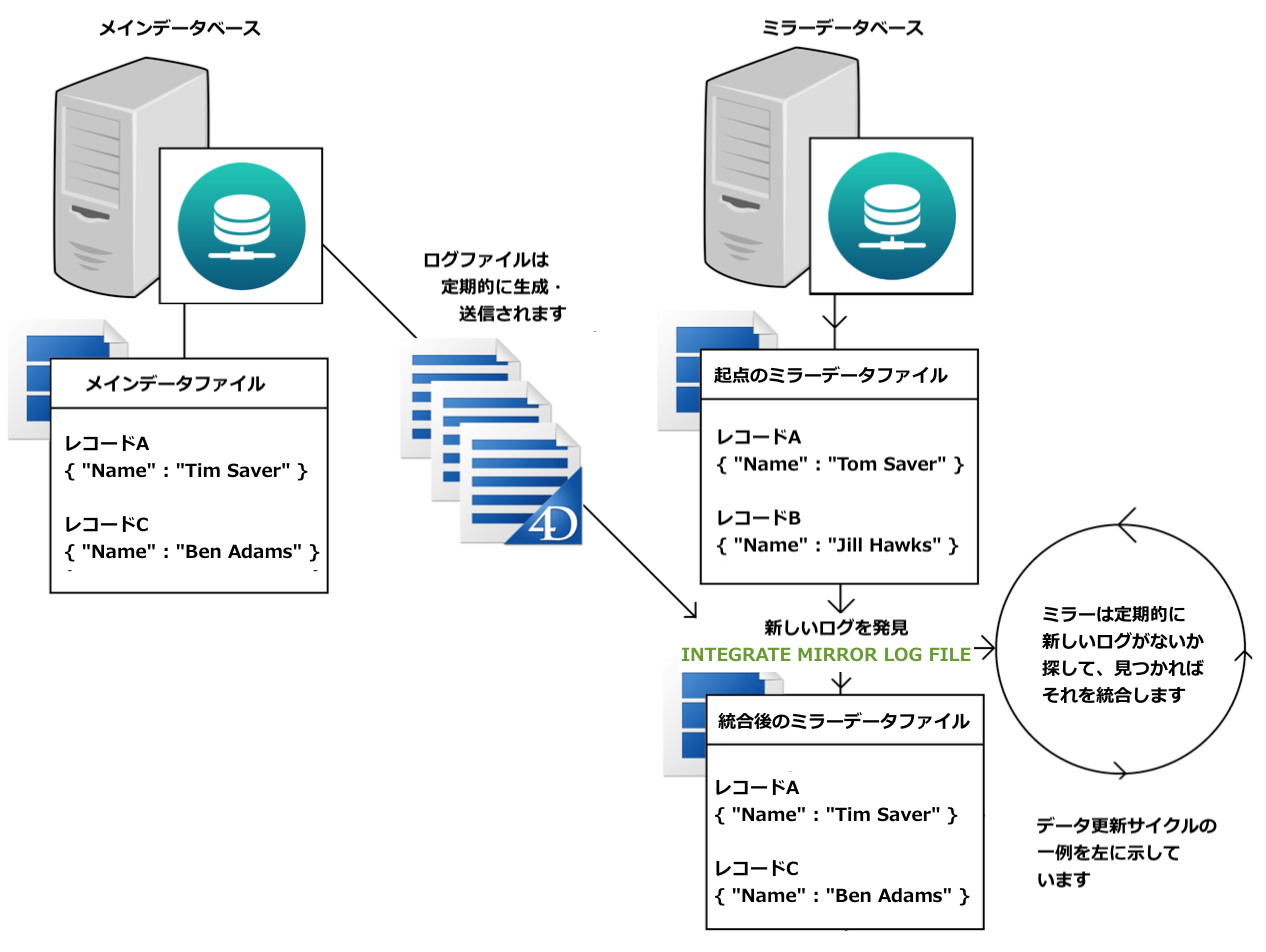
< 図 5 : 新しいログファイルの確認と統合 >
このように、プロセス自体は単純明快です。ログファイルの生成・送信・統合という3つのステップを定期的に実行することで、正確性の高いミラーデータを維持することができます。
ミラーを使った復旧
データベースに損傷を与えるような事故は偶発的に起こるものです。例えば、なんらかの電源トラブルよってデータベースをホストしているマシンが適切にシャットダウンされなかったとします。その後、マシンの方は問題なく再起動したのに、データベースが破損していて開始できない場合を考えてみましょう。このようなケースで、データベースがミラーリングされていて、かつミラーの方で同じ(または別の)トラブルが発生していなければ、復旧作業は非常に短くできる可能性があります。
ミラーデータの利用
メインのデータファイルは破損しており、ミラーによって維持されているデータファイルと比較すると、もはや信頼できません。そのため、復旧作業にはミラーデータベースのデータファイルを使用します。
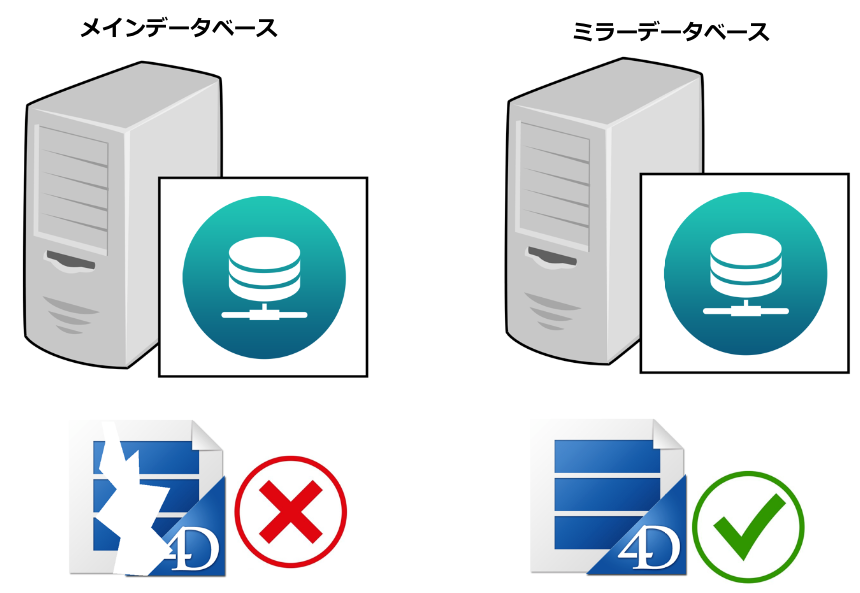
< 図 6 : メインデータファイルが破損しても、ミラーのデータファイルが使えます >
カレント・ログファイルの統合
ミラーはウォームスタンバイとして設定されているため、そのデータファイルはすべてのデータ操作を反映していない可能性があります。幸いなことに4Dのログシステムは、データファイルに対するすべての操作をリアルタイムで記録しています。メインデータベースに残るカレント・ログファイルをミラーのデータファイルに統合すれば、トラブル直前のデータが復元できます。ログファイルの転送間隔が短いほど、カレント・ログに含まれる操作数は少なくなり、結果的に統合にかかる時間も短くなります。
緊急時のデータおよびログファイルの取り扱いには細心の注意を払い、慎重に行わなくてはなりません。間違った操作をしてしまうと、復旧に必要以上の時間がかかってしまいます。 ログとデータファイルは、二つの方法で統合できます。
手動で統合する
一つめの方法は、ミラーサーバーにおいてINTEGRATE MIRROR LOG FILEコマンドを引き続き使用して、メインのカレント・ログをミラーのデータファイルに統合することです。問題が発生したあともミラーサーバーが継続して動いており、ミラーマシン上で作業する場合、これが効率的な方法です。
再起動したメインマシンからカレント・ログをミラーマシンにコピーします。ミラー側では、カレント・ログが見つかった場合にはそれを統合するメソッドをあらかじめ実装するか、もしくはメインサーバーの New log fileコマンドで最後に生成されたログファイル名に準じた名称に、カレント・ログファイル名を変更してやる必要があります。ミラーがカレント・ログを統合し終わると、データファイルの復元は完了です。復元されたデータファイルをメインマシンに転送すれば、データベースを再起動できる筈です。
ただし、留意すべきことがいくつかあります。
まず、データファイルとカレント・ログは対になっているため、カレント・ログをコピーではなくファイル移動でミラーマシンに持ってきた場合には、もし名称を変更していればそれを ”{databaseName}.jounal” に戻し、復元されたデータベースと一緒にメインマシンに転送する必要があります。 正しいカレント・ログが無い状態で復元データベースを起動しようとすると、カレント・ログを新しく生成することになり、ログの記録を開始するためのバックアップ実行が必須となってしまいます。バックアップを実行する分ダウンタイムが長くなり、データベースのサイズが大きい場合には大変な問題になる可能性があります。
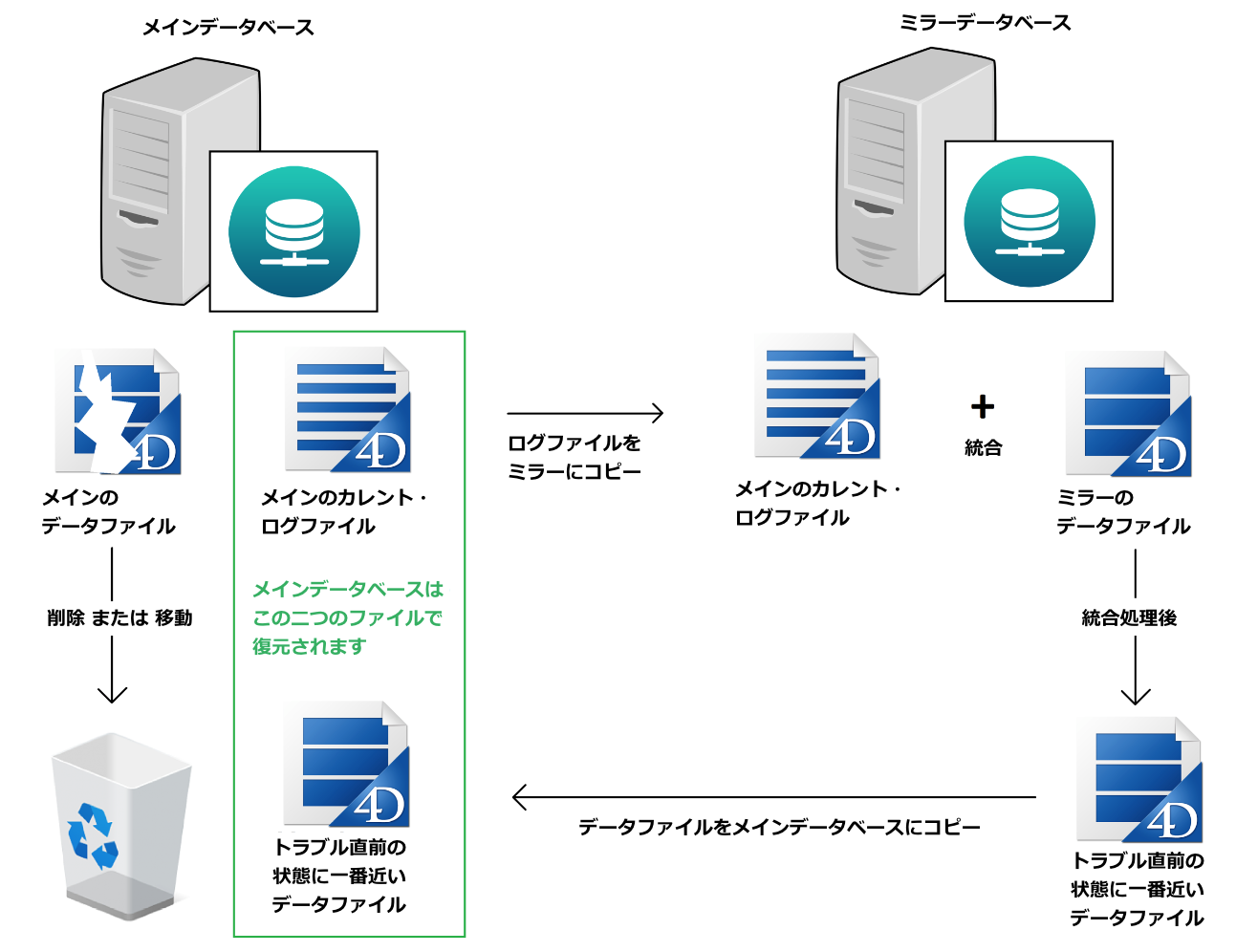
< 図 7 : 手動による統合プロセス >
もう一つの留意事項は、復元時点においてメインデータベースのカレント・ログに記録されている操作は、復元作業を経てミラーデータベースに統合済みであることです。復元データベースの起動後に統合済の操作を含んだログが転送されてきた場合、ミラー側で厳格な統合モードを用いてログ統合処理を行っていればエラーが発生する可能性があります。これを回避するには、いくつかの方法があります:
- 復元作業を行う前にミラーのデータファイルをコピーしておき、復元後にデータファイルを復元前のものと差し替える。
- メインデータベースの起動直後にログファイルを閉じて、このログファイルは統合処理から除外する。
- 統合処理の際、
INTEGRATE MIRROR LOG FILEコマンドの戻り値である最終操作番号を管理し、次のログの統合はその操作番号から行う。 INTEGRATE MIRROR LOG FILEを自動修復モードで使用して統合処理を行う。
ログの統合を4Dに任せる
二つめの方法は、4Dの[自動復元>データベースが完全でない場合、最新のログを統合する]機能を利用することです。この機能はデータベース起動時に実行され、データファイルがカレント・ログと適合するにもかかわらず、ログに記録された操作がデータファイルに含まれていない場合に、コマンドを呼び出さなくても欠落している操作を自動的に統合します。この方法は、一つめの方法よりも復旧作業が少し簡単になります。
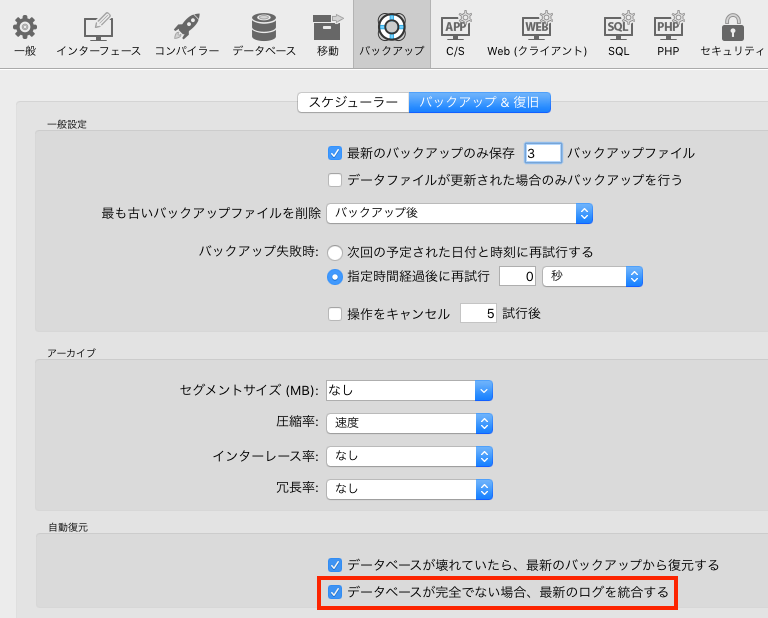
< 図 8 : 欠落している操作を自動的に統合するためのデータベース設定 >
トラブル後にメインマシンが起動したら、ミラーデータベースをシャットダウンし、ミラーのデータファイルをメインデータベースに転送して、破損したデータファイルと差し替えます。その後、メインデータベースを起動します。データベース設定の「バックアップ>自動復元>データベースが完全でない場合、最新のログを統合する」オプションが有効になっている(チェックされている)と、自動的にログが統合され、データベースは正常に動作します。この設定が無効になっていると、データベースは操作が欠落していることを知らせるダイアログを表示し、現在のログファイルを統合するか、新しいログファイルを作成するかの選択肢を提示します。
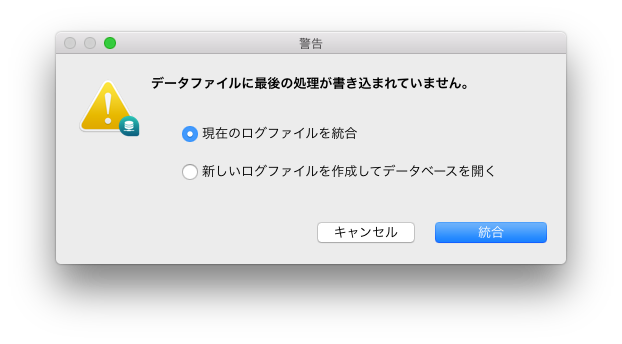
< 図 9 : 「データベースが完全でない場合、最新のログを統合する」が無効になっている場合のダイアログ >
ログを統合しない選択肢を選んだ場合も、データファイルを操作しないか、この状態のデータファイルのコピーを保持していれば、あとからやり直すことが可能です。新しいログファイルを作成した場合も、カレント・ログは失われず、別名保存されてから新しいログに置き換わります。

< 図 10 : 元のログはタイムスタンプの付いた名称で保存され、新しいログファイルが追加されます >
一つめの方法と異なり、この方法ではミラー側の調整は必要ありません。復元したメインサーバーが起動されると、ログの定期転送に伴いカレント・ログは閉じられ、ミラーに送信されて統合されます。
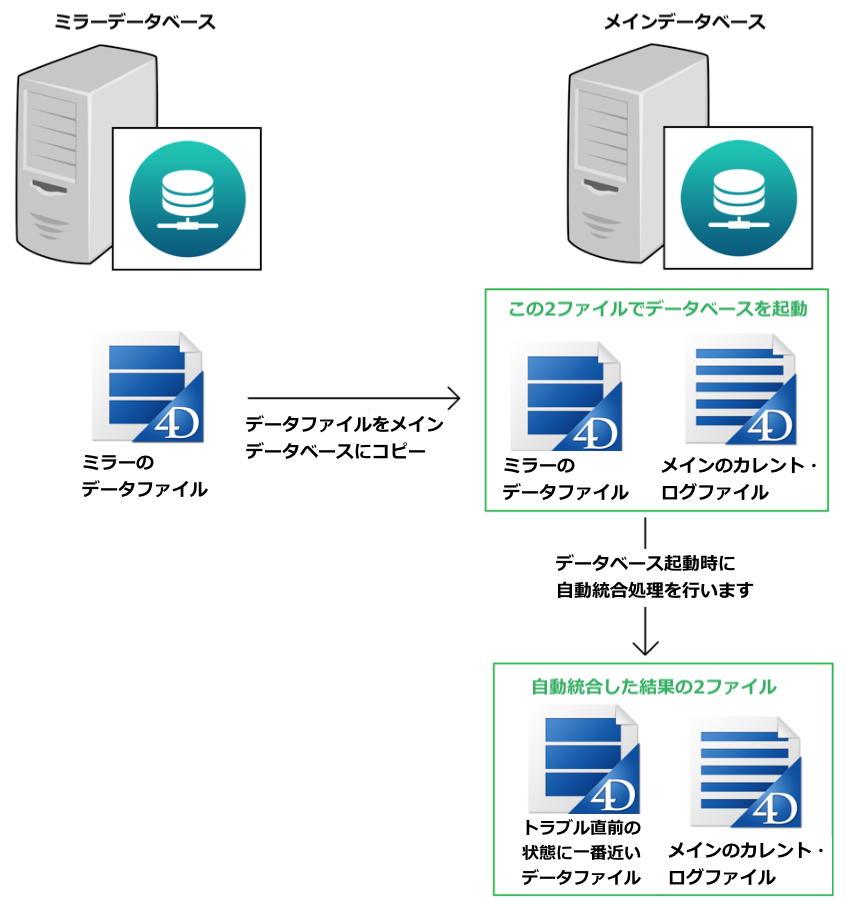
< 図 11 : 自動による統合プロセス >
このように、他のデータベースシステムが遭遇する可能性のあるホットおよびウォームスタンバイデータベースの短所を補うことができます。ホットスタンバイ特有の頻繁な更新は、データベースの反応時間を長くし、パフォーマンスを低下する可能性があります。ウォームスタンバイデータベースでは、ミラーデータが完全に同一でない可能性があります。4Dの機能は、パフォーマンスに大きな影響を与えないウォームスタンバイとしてミラーデータベースを実行しながら、メインデータベースのカレント・ログファイルを統合することによってデータファイルの同一性を実現できます。
プロダクションサーバーとミラーサーバーの再起動
復元されたデータファイルと損傷を受けていないデータベースを使用することで、メインデータベースを正常起動して実行を監視できます。すべて問題なければ、ミラーデータベースも起動します。
ミラーを使用することには、多くの利点があります。ミラーの最も有益な点は、不測の事態が発生した場合のダウンタイムの短縮です。バックアップから復元してログを統合したり、データベースを修復したりした場合と比較して、ミラーのデータファイルを使い、メインデータベースのカレント・ログを統合する方がはるかに速いのです。また、これによりバックアップへの依存度も低くなります。つまり、定期バックアップの実行頻度を減らすことでき、生成され続けるバックアップが消費するディスク領域を削減できます。
おわりに
このテクニカルノートでは、4Dにおけるミラーリングと復元手順について詳しく紹介しました。ミラーリングプロセスでは、基本的に同じデータベースの二つのインスタンスが同時に実行され、片方はデータベース操作が行われるメインデータベースとして機能し、もう片方は同じデータを維持するために操作を「ミラー」(コピー)します。また、ログシステムによって、4Dのミラーリングがどのように簡略化され、データファイルの正確性が維持されるのかについても説明しました。ミラーを使用している場合の復旧作業は、簡単かつ迅速なプロセスです。ミラーのデータファイルとメインデータベースのカレント・ログファイルを統合すれば、復元データファイルでデータベースを再起動できます。高可用性とデータ保護が要求されるケースにおいて、2台目のマシンの用意および維持管理が困難でなければ、ミラーリングの導入はとても有益です。