データベース破損時に便利な 4Dの機能(MSC、バックアップ、ミラーリング)の紹介です。(原文)
はじめに
4Dデータベースは、シンプルにデータを保存したり、データを操作したり、ユーザーにサービスを提供したりするためのツールとして、システムや事業運営に欠くことのできないものです。基幹システムなど、データベースの役割が重要であればあるほど、常時稼働が要求されます。しかし、マーフィーの法則のとおり、「失敗する可能性のあるものは、失敗する」ものです。不測の事態に備えて、緊急時の行動手順を確認しておくことはとても重要です。発生する可能性がある問題は数多くありますが、4Dデータベースが停止している時間を短縮するためにできる対応もいくつかあります。
このテクニカルノートは、二部構成のシリーズの第一部です。ここでは、データベースが破損した場合のダウンタイムを削減するために利用できる4Dの機能(MSC、バックアップ・システム、ミラーリングの概要)について説明します。第二部では、ミラーリングプロセスについて詳しく説明し、ミラーから修復する方法の詳細な提案と実例を提示します。
4Dデータベース
4Dデータベースは通常、データを収集し整理するシステムです。これを拡張することで、ユーザーがデータを扱うための追加機能やサービスが提供できます。データベースは2つの主要なファイル(ストラクチャー・ファイルとデータ・ファイル)で構成されています。ストラクチャー・ファイルには、インタプリタ状態の「.4DB」ファイル、コンパイル済みの「.4DC」ファイルという2つの形式がありますが、データ・ファイルには「.4DD」ファイルしかありません。なお、データインデックス・ファイルの「.4Dindx」など、4Dデータベースに含まれるファイルは他にも多数あります。
< 図 1 : 4Dデータベースのファイル >
データベースの破損
もし 4Dデータベース・ファイルのいずれかが破損すると、データベースが開けなくなったり、使用中にエラーを起こしたりします。データ破損の主な原因となるのは、マシンのクラッシュやハードウェア障害、さらには停電などの予期できない出来事です。これらによって、何か重要な変更、フラッシュの実行、またはデータ・ファイルの変更などの最中にアプリケーションが突然終了することがあります。破損したデータベースが正常に実行できないと、ユーザーがデータやサービスにアクセスできなくなるため、データベースの復旧は時間との戦いになります。
4D には、直近のデータをできるだけ多く含む形でデータベースを復旧するためのツールや機能がたくさんあります。その準備には少々時間がかかるかもしれませんが、備えあれば憂いなしです。これから復元の方法や、事前に準備する必要があるものについて説明します。これらの機能を活用してデータ損失を防ぎ、データベースの停止時間を短縮することで、障害の影響を最小限に留めることができるのです。
メンテナンス・アンド・セキュリティ・センター (MSC)
問題が発生した時に行うべき最初の作業の一つは、メンテナンス・アンド・セキュリティ・センター(Maintenance and Security Center / MSC)を使用してデータベースを開き、ストラクチャーとデータの両方に対して検証を実行して、4Dが特定できる問題がないかどうかを確認することです。 データベースを開けない場合は、データベースを選択しない状態で4Dまたは4D Serverを起動してからMSCを開きます。すると、データベース選択ダイアログが開き、MSCでデータベースを開くことができます。MSCは「ヘルプ」メニュー、またはツールバーが表示されている場合はツールバーのボタンをクリックして開きます。
< 図2:ヘルプメニューからMSCを開く >

< 図3:ツールバーの右端にあるMSCアイコン(左) >
データベースを開けない場合のもう一つの方法は、「上部ファイルメニュー>開く」でローカルデータベース選択ダイアログを表示させ、オプションの選択で開く方法をMSCに変更する方法です。

< 図4:ローカルデータベース選択ダイアログの開き方のオプション(ドロップダウンメニュー) >
< 図5:「開く」オプションのドロップダウンにあるMSCオプション >
検証
検証は、データベースのデータ・ファイル(レコード)、データインデックス・ファイル(インデックス)、およびストラクチャー・ファイル(アプリケーション)のいずれに対しても実行できます。 検証中にエラーや警告を検出した場合にはその内容が、問題ないと思われる場合にはOKが返されます。結果はすべてログファイル(XML形式)に記録され、表示して確認することができます。
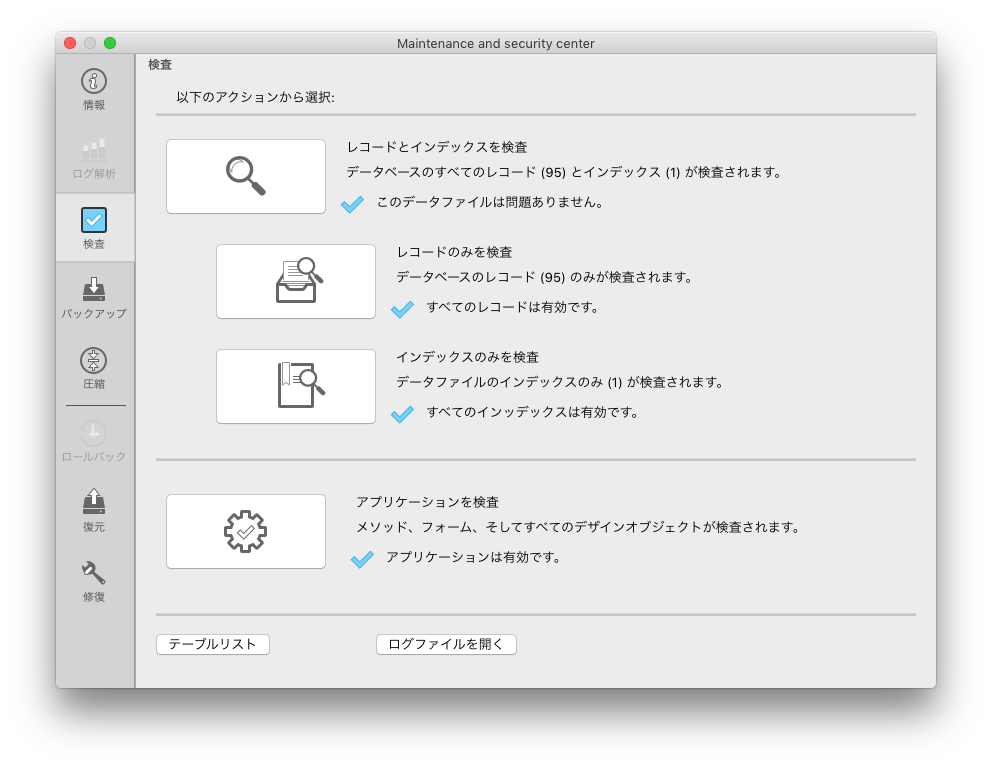
< 図6:MSCの検証タブ(有効な結果を返した場合) >
修復
問題が見つかった場合、MSCの修復機能で解決できる場合があります。修復前にデータベース全体のコピーを作成しておくと便利です。修復対象となるのはデータ・ファイルまたはストラクチャー・ファイルで、検証中に見つかったエラーに応じて、関連する修復を実行します。なお、検証なしに修復を実行することもできます。この場合、検証を行わない分、時間を節約できます。運用しているデータベースが検証にどれくらいの時間を要するのか、あらかじめ知っておくことも緊急時の役に立つでしょう。
修復を実行すると、ログファイルが生成されます。エラーが修正されていることを確認するために、検証を再実行することも重要です。ある損傷箇所が別の問題を隠してしまう場合があるため、検出も修復もできなかったエラーが新たに検出される可能性があります。このような状況では、エラーがすべて修正されるまでプロセスを繰り返す必要があります。
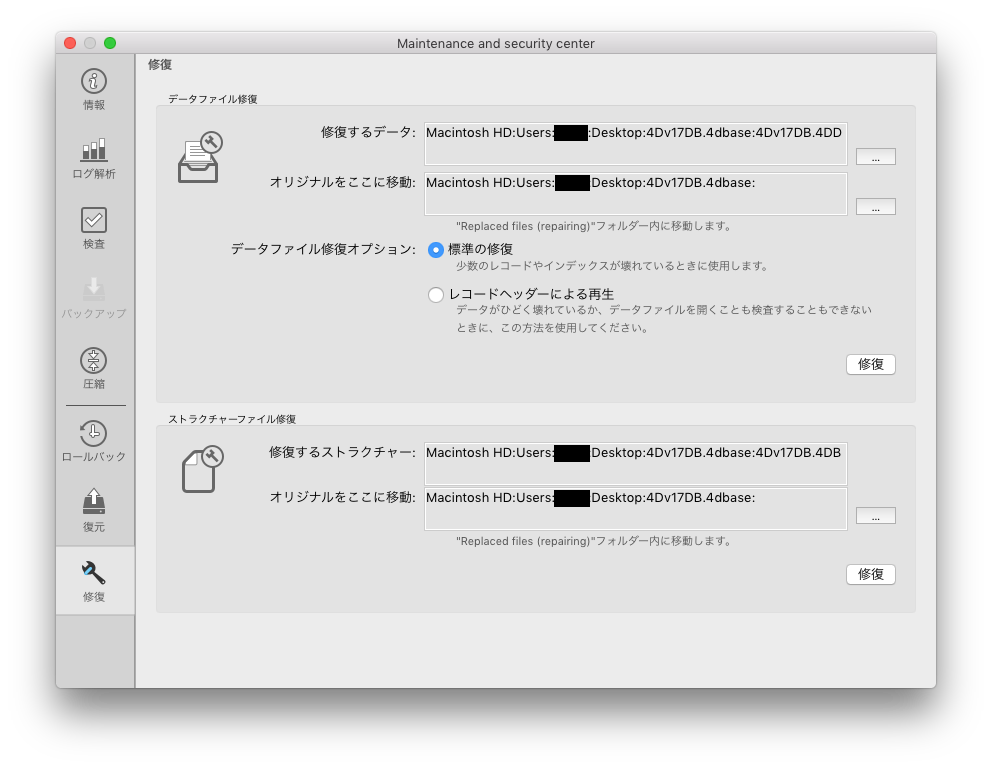
< 図7:MSCの修復タブ >
修復は修復前ファイルの自動コピーを伴うため、ハードドライブの空き容量が必要になります。
ストラクチャー・ファイルには一つの修復方法しかありません。ストラクチャー・ファイルを修復した場合、修復前のストラクチャー・ファイルとストラクチャー・インデックスがタイムスタンプの付いた”Replaced Files…”フォルダーに保存され、修復されたファイルがメインの場所に置き換えられます。
データ・ファイルの場合には二つの修復オプションがありますが、[標準の修復]オプションを最初に試すことをお勧めします。修復できない場合は、[レコードヘッダーによる再生]を試します。データ・ファイルの修復が実行されると、修復前のデータ・ファイル、データ・インデックス、およびジャーナルファイルがタイムスタンプの付いた”Replaced Files…”フォルダーに移動し、修復されたデータ・ファイルで置き換えられます。データベースを起動すると、新しいデータ・インデックスが自動生成されます。新しいジャーナルファイルは生成されませんが、”Replaced Files…”フォルダーにあるものを、コピーして戻すことができます。ジャーナルファイルが見つからない場合、データベースはジャーナルファイルに関する警告を表示し、新しいジャーナルファイルを作成するか、既存のジャーナルファイルを検索して選択するかを選べます。
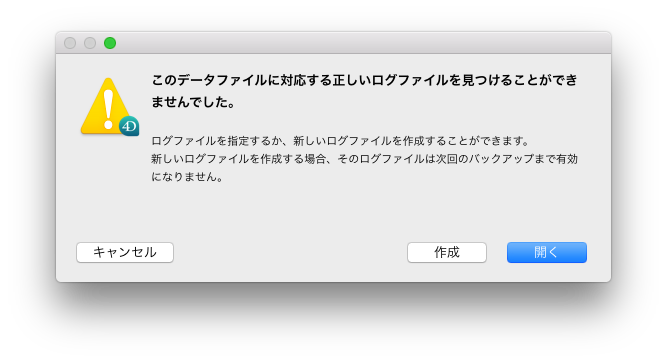
< 図8:ジャーナルファイル(=ログファイル)が見つからない時のエラーダイアログ >
MSCの検証と修復機能を利用するには、問題発生前の準備が必要ありません。問題が発生した後で検証や修復を必要なだけ実行することができます。
ですが、この修復システムは包括的な解決策ではありません。ファイルがひどく損傷している場合は、MSCの修復機能では修正できません。このようなケースに備えて、次善策「プランB」を用意しておくことが有益です。
バックアップ・システム
4Dにはバックアップ・システムがあり、アプリケーションの用途に合わせて機能をカスタマイズすることができます。4D v14で、レコード識別にプライマリキー(主キー)を用いるようジャーナルシステムが改良されたことにより、バックアップ・システムの信頼性はより一層高まりました。データ・ファイルへの変更は、カレントログである”.journal”ファイルに主キーを使って記録されます。バックアップを実行すると、バックアップ・ファイル”.4BK”とログファイル”.4BL”が生成されます。

< 図9:.4BKと.4BL、.journalのサンプル >
”.4BK”ファイルには、データベース設定のバックアップ設定で選択されたファイルが含まれます。初期設定では、データ・ファイルとストラクチャー・ファイルが含まれます。
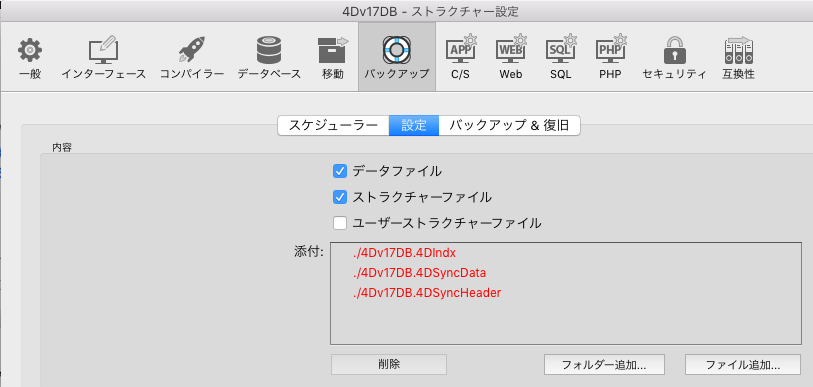
< 図10:データベース設定のバックアップ設定ページ >
MSCでは修復できない大きな問題が発生した場合は、バックアップから復元した上でログを統合することで、データ・ファイルに対して行われた直近の変更までを復元することができます。
バックアップの準備
バックアップ機能を利用するには準備が必要です。前述のように、データベースの復元にはバックアップ・ファイルを使います。バックアップが存在しなければ、バックアップからの復元はできません。この準備ですが、さほど難しくはありません。
まず、バックアップは指定したデータベースファイルのコピーを作りますので、ディスクスペースを確保する必要があります。巨大なデータ・ファイルを持つデータベースの場合、一つ一つのバックアップ・ファイルが多くのディスクスペースを使用するため、バックアップ専用のスペースをあらかじめ計画しておく必要があります。バックアップは、BACKUPコマンドを使用する以外にも、次の図に示すように様々な方法で生成できます。
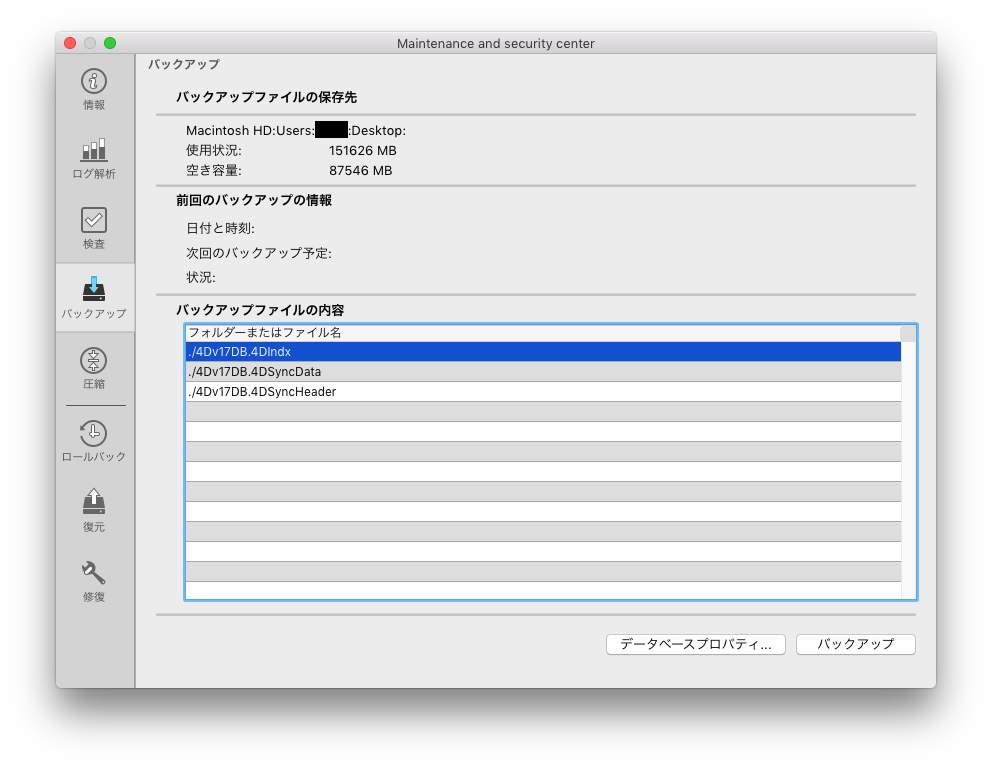
< 図11:MSCのバックアップ・タブ >
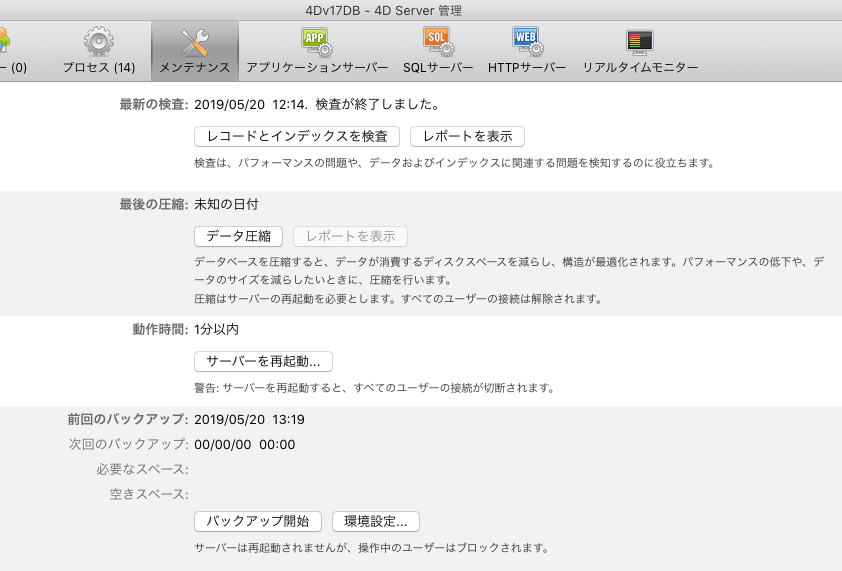
< 図12:4D Serverの管理ウィンドウのメンテナンス・タブ >
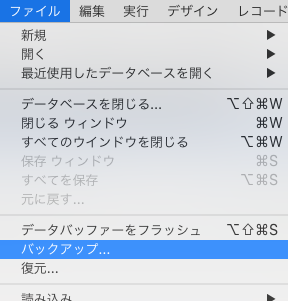
< 図13:ファイルメニュー >
データベース設定のバックアップスケジューラー・オプションで、定期的な自動バックアップを設定することもできます。バックアップ処理はデータベースをロックするため、大規模なデータベースでは、利用が少ない時間帯を狙ったバックアップ計画をお勧めします。
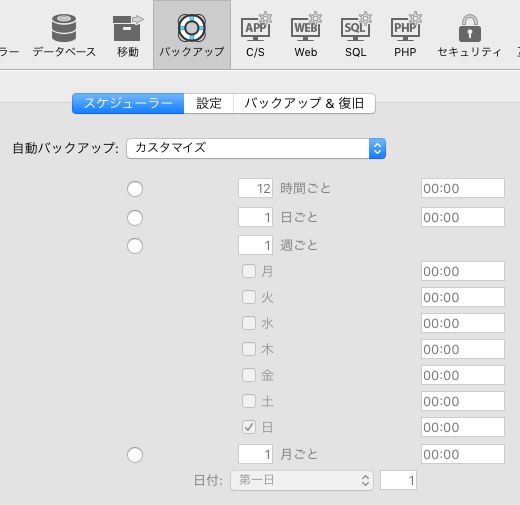
< 図14:データベース設定のバックアップスケジューラー・ページ >
定期的にバックアップが生成されるようデータベースを設定することは是非とも検討すべきです。バックアップ設定は外部ファイル{データベースフォルダー}\Preferences\Backup\Backup.xmlに保存されます。アップデートや復元をする際にはこのファイルを維持することが重要です。バックアップ・ファイルがあると、復元だけでなくロールバックを実行することもできます。どちらの機能を使うのかは、問題発生の状況によりけりです。
復元とロールバック
バックアップがあれば、リカバリーの選択肢が増えます。バックアップによって提供される二つの主な機能は、バックアップの復元とロールバックの実行です。復元の場合、バックアップ・ファイルは圧縮されたアーカイブ(zipファイルなど)のようなもので、正常に機能していた古いバージョンのデータベースを解凍して使うようなイメージです。これに対し、データ・ファイルへの操作を一部「なかったことにする」処理がロールバックと言えます。
バックアップからの復元
データベースが損傷を受けるなどして、データベースを以前の状態に戻す必要が生じた場合は、データベースのいずれかのバックアップからの復元が可能です。復元の最も簡単な方法はMSCから実行することですが、この他にもファイルメニューやコードを使う方法もあります。ほとんどの場合、すべてのファイルはバックアップ生成時の状態で復元され、指定の場所に置かれます。通常は最新のバックアップが選択されますが、場合によっては、古いバックアップが必要になることがあります。MSCでは、ジャーナルファイルを統合するオプションが提供されます。これにより、バックアップに含まれない直近の操作をデータベースに統合し、データの損失を減らすことができます。
ロールバックの実行
バックアップ機能を使用している場合、MSCからロールバックを実行することができます。ロールバックはバックアップを復元してから任意の操作までのジャーナルを統合します。例えば、大量のレコードが誤って削除または変更されてしまったものの、それまでにも何時間もの作業が行われている、という事故が発生した場合です。MSCのロールバックタブを開くと、データ・ファイルに対して行われた操作が一覧表示され、バックアップが存在する場合は、任意の操作を実行した状態に戻すことができます。バックアップが存在しない場合、MSCのロールバック・ページにはアクションが表示されますが、ロールバックを実行することはできません。
ロールバックはカレント・ジャーナルの範囲内でのみ実行できます。それより古い時点へのロールバックが必要な場合は、まず目的の時点を含むログファイルがカレント・ジャーナルである、相応に古いバックアップを使ってデータベースを復元する必要があります。
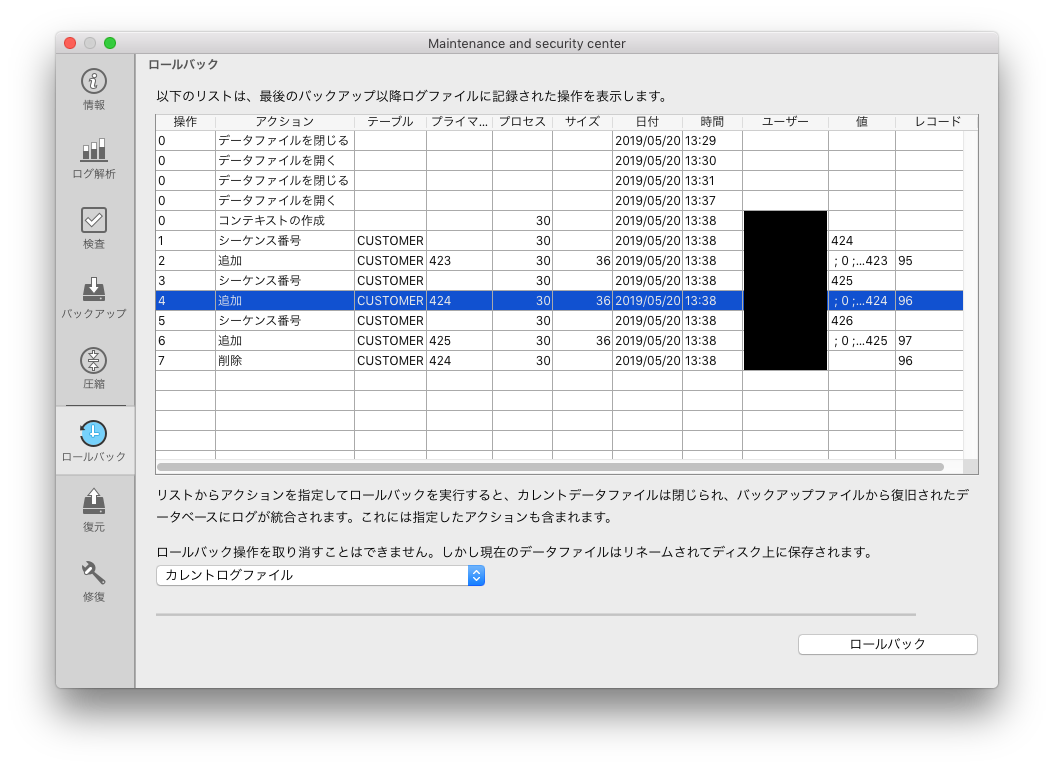
< 図15:MSCのロールバック・タブ >
ミラーリング
ミラーリングは、より高度で複雑な安全メカニズムで、サーバーとして実行される4Dデータベースに実装することができます。4Dでのミラーリングは、データベースのコピーを第2のサーバーインスタンスとして実行し、メインサーバーにおけるデータ操作をすべて、第2インスタンスにも反映させることで行われます。具体的には、メインサーバーにてデータ操作のログファイルを生成し、これを受け取ったミラーサーバーが変更内容を統合します。これは正しく行えば、緊急時に4Dデータベースを正常かつ最新の状態で復旧する最も迅速な方法の一つです。ミラーには大きなロックプロセスがないため、バックアップ中にデータベースがロックされるという問題も解消されます。
ミラーの設定
4Dにはミラーリングを自動的にセットアップする設定がありません。つまり、あらかじめプログラムを書いてデータベースに必要な機能を実装しておく必要があります。ミラーを実装する方法は様々で、これが最善といえる方法はありませんが、実装の中で必須となる項目がいくつかあります。
自己の識別
同一データベースのインスタンスが二つ存在することになるため、ミラーリングを開始するにはまずメインサーバーとミラーサーバーを識別する必要があります。これはOn Server Startupデータベースメソッドで行うのがベストです。識別方法として簡単なのは、ミラー上にのみ存在するファイル(特定の名前を持つ空のテキストファイルなど)を確認することです。フォルダーの存在や設定ファイルの内容の確認など、より複雑な方法をとることもできます。なお、ハードウェア障害に備えて、メインサーバーとミラーサーバーは異なるマシンで運用すべきです。
例:
//On Server Startup メソッド:
//…
C_TEXT($path_t)
$path_t:= Get 4D Folder(Current resources folder)
$path_t:= $path_t + “IsMirror.txt”
If(Test path name($path_t)=Is a document)
// ミラーサーバーの場合
Else
// メインサーバーの場合
End if
//…
ログの生成
メイン側のデータベースはログを生成する必要があります。ログの生成はNew log fileコマンドを使用して様々な方法で実行できます。このコマンドはカレントログファイルを閉じて、同名の新しいカレントログファイルを同じ場所に生成します。古いログファイルは、現在のログ・チェーンに沿った採番方式で別名保存され、コマンドはそのフルパスを返します。通常はストアドプロシージャーを使って、2〜5分毎の短い間隔で行いますが、ログの生成頻度が高いほど、最新に近いミラーデータを維持することができます。なお、データベースを停止する必要が生じた場合に、ストアドプロシージャーも適切に停止するよう設計しておく必要があります。
例:
// Mirror_GenLogs
// 2分おきにログファイルを生成します
C_BOOLEAN(stopFlag_b)
C_TEXT($logPath_t)
stopFlag_b:= False
REPEAT
$logPath_t:= New log file
DELAY PROCESS(CURRENT PROCESS; 60*60*2) // 60ティック= 1秒
UNTIL(stopFlag_b)| (Process aborted)
ミラーとログを共有する
ログを生成したら、次に必要となるのはそのログをミラーと共有するメカニズムです。これはファイル転送、あるいはファイル共有のケースなので、実行する方法は無限にあります。ファイルが共有ネットワーク上にある場合は、COPY DOCUMENTコマンドでファイルを新しい場所にコピーするという簡単な方法もありますし、もっと複雑な方法を選択する場合もあるでしょう。
ログ共有をメインデータベースのタスクにしてログ送信させることも、ミラーのタスクにしてログ取得させることも可能です。通常は、ログ生成を把握できるメインサーバーにファイル送信させる形をとります。上述のコード例にて、ログ生成後に、そのログを転送するメソッドを呼び出すコードを追加すると下のようになります:
// Mirror_GenLogs
//…
REPEAT
$logPath_t:= New log file
Mirror_SendLog($logPath_t) // ミラーサーバーにログファイルを送信します
DELAY PROCESS(CURRENT PROCESS; 60*60*2) // 60ティック= 1秒
UNTIL(stopFlag_b)| (Process aborted)
//…
ログの統合
ミラーデータベース側においては、新しいログがあるかどうかを定期的に確認し、あれば統合します。前述の実装例の場合、ミラーはログファイルが置かれる場所を短い間隔でチェックする必要があります。また、どのログが新しく統合する必要があるもので、どのログが統合済かを把握するシステムも必要です。
新しいログは、INTEGRATE MIRROR LOG FILEコマンドを使って統合します。このコマンドは2つの必須パラメーターと2つの任意パラメーターを受け取ります。最初のパラメーターは統合するログへのパスです。2番目のパラメーターは、前ログファイルから統合された最後のオペレーション番号で、コマンド実行後には今回統合した最後のオペレーション番号に更新されます。これは、次回の統合処理を見越して保存しておくべきものです。任意の第3パラメータは、統合の際に「厳格な統合モード」と「自動修復モード」を選択するためのものです。厳格な統合モードでは、エラーが発生すると統合が停止され、MSCを使用して状況を調査する必要があります。データの有効性を確認するため、これがデフォルトかつ推奨のモードです。ミラーを維持し、統合を続けるには、自動修復モードを使用して、見つかったエラーを自動的に修復することもできます。エラーが見つかった場合、情報はコマンドの4番目で任意のオブジェクトパラメーターに返されます。
ミラーを緊急稼動するための準備
メインデータベースで問題が発生した場合、それを解決できるまではミラーをメインデータベースとして機能させる必要があります。すべての接続をメインデータベースからミラーへルーティングするための計画が必要になります。接続数や、依存関係にあるシステムの構成に応じて、転送処理は単純にも複雑にもなりえます。
ミラーリングの開始
ミラーリングを開始するには、まず最初にメインデータベースを起動してバックアップすることで、ログ・チェーンを開始する必要があります。その後、バックアップしたデータベースを一旦閉じ、データベースとすべてのファイルをミラーの場所にコピーします。改めてメインデータベースを起動させ、ログ生成用の自動プロセスも開始します。次にミラーを起動します。ログファイルは、ミラーデータベースが監視している場所に送信されていきます。ミラーは新しいログファイルを統合していき、結果的にメインデータベースと同じデータを格納した第二のデータベースが維持されます。
メインデータベースで緊急事態が発生した場合、ミラーサーバーをメインサーバーとして機能させます。問題が解決した後は、再度バックアップを取るところからミラーリング開始手順を初める必要があります。
ミラーリングの実装には複数の方法がありますが、基本となる機能は含まれていなければなりません。メインサーバーは定期的にログを生成し、それらを統合するミラーサーバーに送る必要があります。また、ミラーは一つに限定されません。複数のミラーを複数の方法で実装し、安心が得られるレベルまで作り込むことができます。ミラーのミラーを用意して直列的なミラーチェーンを作り、緊急事態に一つ目のミラーをメインサーバーとして動作させている間も、次の緊急事態に備えて引き続きミラーリングが継続されるような設計が可能です。あるいは、並列的に一つのメインサーバーに複数のミラーを用意することもできます。ミラーリングの設定は比較的難しく、多くのリソースを必要とする場合がありますが、病院のデータベースなど無休で稼働させ続けなくてはならないケースへの対応策ともなります。
おわりに
このテクニカルノートでは、データベースが使用できなくなるような緊急事態への準備と対応について説明しました。ファイルが単純に破損した場合、MSCの修復機能によってデータベースを復旧できることがあります。被害がもっと深刻な場合は、復元に使えるバックアップ、またはすぐに使用できるミラーを準備しておくと便利です。容易に元に戻すことができないデータ事故の場合にバックアップがあれば、事故前の時点までロールバックすることができます。いずれの方法も、できるだけ多くの直近データを含む形でデータベースを復旧させ、ダウンタイムを可能な限り短縮するのが目的です。
このテクニカルノートの第二部ではミラーリングについてもっと詳細な情報を例とともに紹介します。